We Lacked This: Monte Carlo Velocity Forecasting Tool
We couldn’t find a simple — and free — tool for forecasting our Agile deliveries based on team data we had at Panaxeo. We were sad for a bit, but then our chief agile person, Adam, created one. So, here it is for you, for free, because that’s how nice we are.
Read this article written by Adam himself to know when and how you can use it in your own practice.
Data-driven Velocity Forecasting with Monte Carlo
Editor’s Note: I will be referring to predicting a team’s future output as forecasting (mainly to remain consistent with the 2020 version of the Scrum Guide). If you are used to the term “estimating”, you can think of them as equal for the purpose of this text.
Anatomy of a good forecast
A good forecast has a predictive value of the future. By nature, it is probabilistic for all but the simplest of tasks. Also, it represents the uncertainties fully and transparently.
Take this example of Team Edison’s past velocities:
10, 15, 0, 5, 10, 15
What would be a good forecast for their velocity in the next sprint? Is it 9 story points (the mean)? Or is it 9.1±5.8 (including standard deviation)?
Neither tells the whole story. Remember, by forecasting, you want to answer a simple question: What are the possible future outcomes and how likely are they?
Neither the point forecast nor the simple range forecast can give an answer like that. They communicate no confidence of achieving an outcome, yet confidence is a decisive factor when we commit to a forecast.
A probabilistic forecast
Let me introduce you to a simple way of creating probabilistic forecasts which honors the spirit of “good forecasting”. The method is called Monte Carlo.
The basic premise — take a piece of a previous effort (e.g., a story point) and its actual duration. Keep doing this at random until you reach the capacity of your next sprint. This yields a hypothetical next sprint with a hypothetical velocity sampled from the hard evidence of your past performances.
The magic happens when you do this enough times and plot the outcomes. And by enough, I mean a LOT. Without unnecessarily delving into statistical theory, let’s say 10K will suffice.
With the data in hand, you can answer the central forecasting question easily — how many % of times is the hypothetical velocity smaller than X? If you want 85% confidence, make X = 0.85.
Why this method works well is a deeper topic with many good resources if you’re curious.
An example of a probabilistic forecast
A word of caution
There are many nice things about this method, making it a useful assistive tool for forecasting large chunks of the backlog potentially several sprints into the future:
It is data-driven.
It takes variance into account.
It directly translates into realistic statements, including (un-)certainty.
Thanks to the fair consideration given to all previous sources and the effects of variances, it doesn’t need additional contingency buffers. They are baked-in.
However, there are certain limitations:
The output metrics (story points in this example) must be well-defined and consistent. For Scrum teams, this means having a consistent Definition of Done and a well-founded relative sizing practice.
The data should be (reasonably) stationary to achieve a (reasonably) accurate forecast; in a nutshell this means the past velocities should not depend on time (velocity X was equally likely to happen in 1st, 5th or 12th sprint). Non-stationarity typically happens when disruptive changes produce a new source of variation which carries on to the rest of the series. Imagine substantial changes to the team’s composition, process, environment, or Definition of Done, etc.). If this is your case, consider using only data starting after your last disruptive change occurred.
Finally, as with any quantitative method, having more data increases the predictive power.
Neither is a reason not to run the Monte Carlo in your own forecasting process. But be aware of the limitations and act conservatively on the outputs, at least until your environment stabilises again.
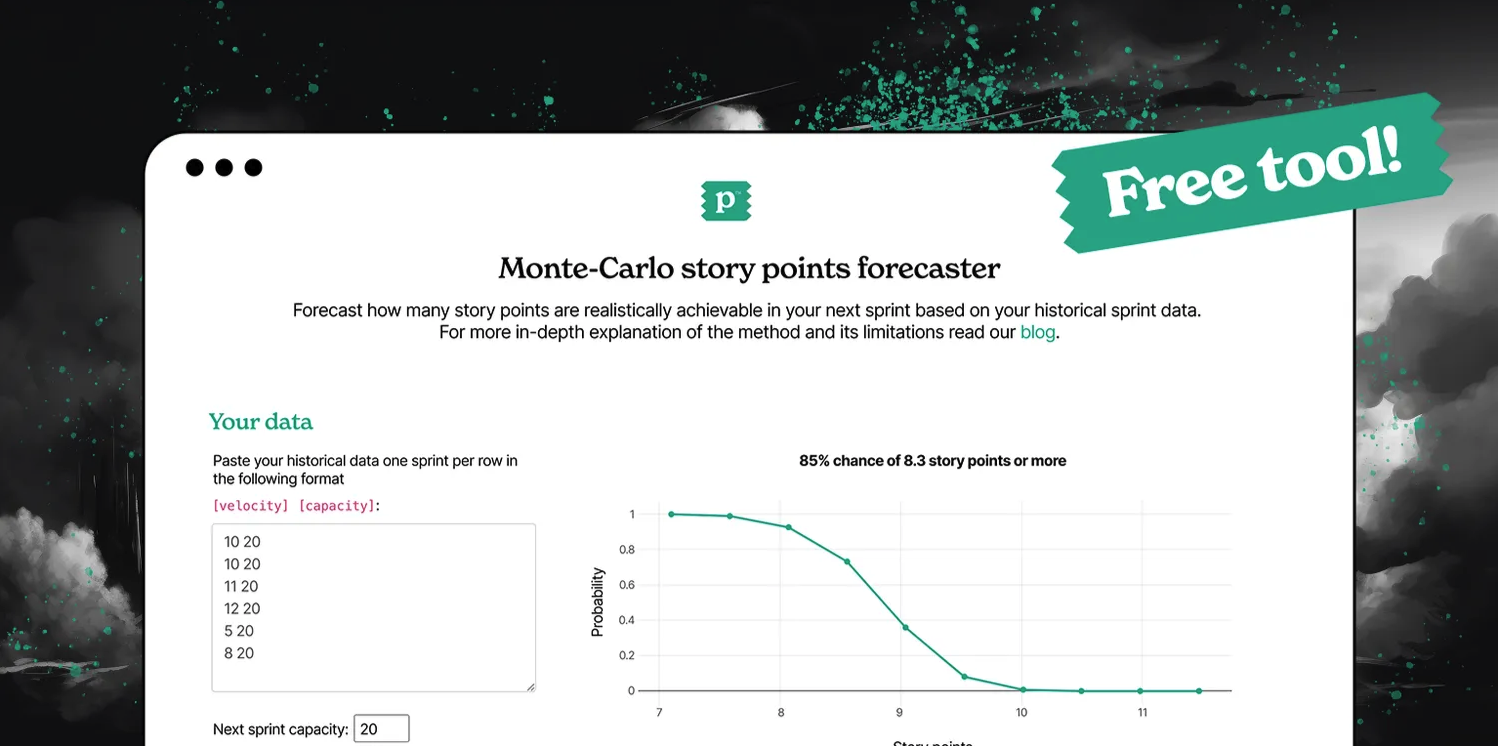
Try it now for free
If you like this method, good news! You don’t need to do all this work by hand or purchase a costly project management tool.
Head to tools.panaxeo.com/mc/, paste in a few numbers, and get your forecast in seconds (for free & without registration).
You can experiment by removing your latest sprints and forecasting the following ones with the tool. Was it accurate? If not, were there any disruptions? In data science, this practice is called cross-validation. It’s a good way to gain additional confirmation of a forecasting method.